Why should the Enterprise Control and Information Systems Architecture be divided into "Levels", and how many such Levels should there be ?
The number of Levels in an enterprise architecture is not determined by the PERA model, but rather is a result of the requirements of the enterprise. Typically this is 5 to 7 Levels, but it may be more or less than this number. The lower levels (at the industrial facility) are fixed by the nature of activities required of them.
FIGURE 3
EXAMPLE LEVELS AND ASSOCIATED APPLICATIONS
|
|
|
TIME FRAME FOR: . Response . Resolution . Reliability . Repairability |
| LEVEL 5 | PRODUCTION PLANNING ACCOUNTING SUPPLIER RATING COMPUTER ASSISTED DRAFTING & DESIGN MAINTENANCE COSTING |
DAYS TO WEEKS |
| LEVEL 4 | PRODUCTION SCHEDULING MAINTENANCE SCHEDULING MANUFACTURING RESOURCE PLANNING MATERIAL/PRODUCT TRACKING SITE-WIDE PRODUCTION REPORTING |
HOURS TO DAYS |
| LEVEL 3 | AREA OPTIMIZATION PRODUCTION DATA HISTORY MAINTENANCE MONITORING |
MINUTES TO HOURS |
| LEVEL 2 | OPERATOR INTERFACE OPERATOR INTERFACE UNIT OPTIMIZATION TRENDING (CHART RECORDER REPLACEMENT) REAL-TIME STATISTICAL PROCESS CONTROL |
SECONDS TO MINUTES |
| LEVEL 1 | CONTROL INTERLOCKING |
MILLISEC TO SECONDS |
| LEVEL 0 | SENSORS ACTUATORS |
CONTINUOUS |
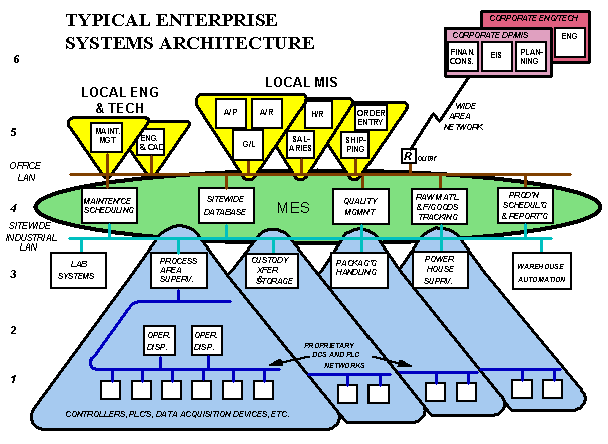
The Levels in the Control and Information Architecture are aligned between the Physical Architecture (Computer and Network Hardware) and the Logical Architecture (Software and Network configuration).
Fundamentally, what is needed is an "Architecture" within which the application software and hardware are implemented with a communications network. However, this Control and information System Architecture" must support the application software on processors distributed at the correct level to allow them to achieve adequate response, resolution, reliability, and repairability. These processors are then connected by a communications network capable of flexibly moving data as with an appropriate level of speed and security.
These "4 R's" of networking provide a mechanism for separating applications and placing them at the correct level in the information architecture.
| Level 1 | Samples taken several times per second are used by a Level 1 controller to recalculate the position of a flow control valve. |
| Level 2 | "5 second" samples are displayed on a Plant Process CRT. |
| Level 3 | "1 minute" averages of the flow rate are used by a plant area optimizer or an alarm/trip system. |
| Level 4 | "1 hour" integrals are used for performance calculations. |
| Level 5 | "1 month" integrals are used for planning feedwater heater preventive maintenance inspections. |
When considering plant control and computing devices and the networks which connect them, a key consideration is the ease with which these devices can be maintained. For example, many continuous processes cannot easily be shut down to repair control devices such as PLC's (Programmable Logic Controllers) or DCS's (Distributed Control Systems). These devices and the proprietary networks connecting them must be maintainable "hot", (ie. changing boards with the power still applied), to avoid shutting down associated equipment.
These Repairability requirements apply to software as well as hardware. Reloading, reconfiguration, and software correction may be necessary with the systems "online". This places very fundamental design constraints on the software.
Conversely, office computers and LAN's (Local Area Networks) can usually be shut down for maintenance, or to connect new devices with little adverse effect.
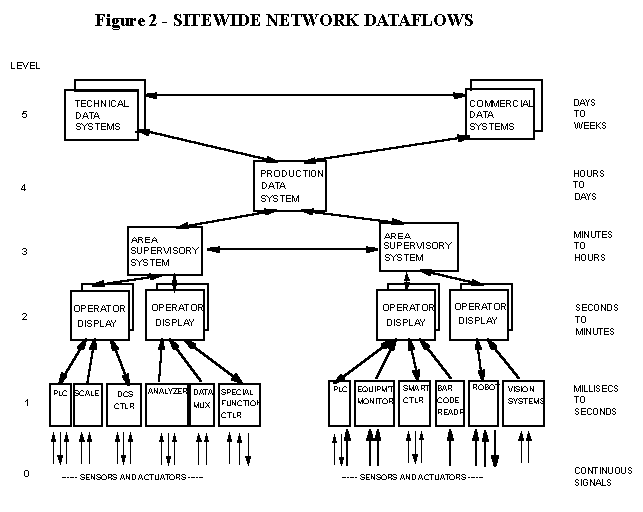
Design of the "logical" network architecture is the first step in designing a network. At this time data-flows between programs and data bases is evaluated, often in the form of conventional "data-flow diagrams". An example of "Network Dataflows" is shown in Figure 2.
Application programs must be positioned at the appropriate level in the information architecture to satisfy the Response, Resolution, Reliability, and Repairability requirements of the application. Figure 3 shows the kind of applications which one might expect to find at each level in a plant.
The positioning of applications is very dependent upon the requirements of that particular plant and site. It is quite possible that a given application might exist at level 3 in one plant, and at level 4 or 5 in another. Also, most applications span several levels. Possible "multi-level" examples include quality management, production reporting, material tracking, and maintenance.
In some cases, applications may reside on a dedicated processor; in other cases they may share a processor with other applications.
Clearly, several different applications operating at different levels may require access to the same piece of production information (eg. input flow rate). It is not practical to have each system independently request this piece of data from the level 1 device to which the sensor is connected.
In most cases, access of data is primarily from an application which is one level higher in the architecture. However, this is not always the case. For example, a level 5 engineering system may require one minute averages (Level 2) for the purpose of process unit studies. Similarly, Level 5 cost information may be provided to Level 2 or 3 optimization algorithms. None-the-less, inquiries spanning more than one level are the exception, and in general the network should be designed to optimize communications between adjacent Levels.
As data moves up through the architecture, it tends to become increasingly summarized. It also concentrates from many devices and data highways at the lowest levels, to a single production database at level 4. This Level 4 system also provides the "gateway" through which the "office systems" view the plant data, and through which plant systems view "office" information. Interestingly, as data moves up from Level 4, it tends to "fan out" again, into various commercial and technical systems. The Level 4 Database is therefore a "nexus" for all data moving from, or to, the operations level.
A principal difference in the appearance of the Sitewide Network and the Network Dataflows results from the ability of modern networks to allow any device on the highway to communicate directly with any other device. For example, it is possible for a Level 4 "Sitewide Database" to get data from a Level 3 Supervisory computer. However a Level 3 system may exchange data directly with another Level 3 supervisory system.
Communications in the network may range from 4-20 milliamp analog signals, to "star-connected" RS232 digital links, to high speed co-axial or optical highways. Each of these kinds of connections has a role, and indeed also has its own messages in terms of impact on the Response, Resolution, Reliability, and Repairability of that part of the network.
Discretionary programming makes possible integration of communications protocols from different vendor's proprietary networks. Typically, a single Level 3 Processor may integrate information from several lower level devices or networks.
These operating systems, such as NT, Unix, and others, provide an environment which can support the full 7-Level OSI/ISO communications model. (Note: in the future, this capability may be available at lower levels but this is not feasible at present due to lack of established standards and cost effective interfaces).
Sitewide Networks may be implemented using;
o "Broadband" technology (ie. with several channels sharing the same transport medium as with Cable TV broadcasts)
o "Baseband" (eg. Ethernet or Token Ring)
o A combination of the two (eg. Broadband "trunks" with Baseband Radial links).
o Point-to-point Links
For obvious commercial and technical reasons, control system vendors are very reluctant to allow users and other vendors to connect devices directly to their "proprietary data highway".
For this and other reasons, A "PROPRIETARY" NETWORK SHOULD NEVER BE USED AS THE PLANT WIDE INDUSTRIAL NETWORK. This network forms the foundation for a Plant Wide System and must be "open" to allow connection of a wide range of systems from various vendors.
Also, since a proprietary network is not based on agreed, published standards, it will almost certainly "evolve" over time. As a result, even if a user standardizes on a single vendor, he will probably still encounter long-term compatibility problems in expanding his system.
Working with an industry-standard network also maximizes the likelihood of being able to purchase device interfaces for any "3rd Party" equipment which may be acquired in the future.
One exception may be "Broadband Trunks" where "logically" separate channels may share "physical" transport media. However, the Broadband network must then operate at the Response, Reliability and Repairability level of the most critical industrial application that it carries.
Similarly, an Industrial LAN cannot afford to be "clogged" by large volumes of data processing information, such as would routinely be transferred on the Office LAN. Otherwise, critical control or alarm data might arrive too late.
The Office LAN typically has much lower response, reliability, and repairability requirements than the Industrial LAN. Industrial networks are often specified in such a way that "worst case" transmission delays of much less than a second can be guaranteed, whereas office LANs may sacrifice guaranteed response time for more efficient use of the available communications bandwidth. In the Industrial Network, failure of a single program or hardware interface to the highway must never "bring down" the whole network. However, elaborate precautions such as redundant data highways, are rarely justified in the office environment.
In many cases, a secure "gateway" is necessary between the two networks. This "gateway function" may be performed by the same processor as used to implement the Level 4 Site-Wide production Database, or it may be a separate processor.
This gateway performs several functions.
Since the "environments" for operation of an Office Network and an Industrial Network are so fundamentally different, a level of protection is required between the networks. Commercial and Technical programmers on the Office LAN should not have to worry about possible consequences of their programming activities on the Industrial Network, or worse still on plant equipment!
Some data transfer between these levels is, however, essential. If optimization of the plant is to be accomplished, some cost information must be available to plant level systems. Similarly, production throughputs, losses and quality data, must be made available to "front office" systems. what is needed then is a "filter" which will allow certain kinds of pre-specified access.
Furthermore, it may be necessary to implement a "release" mechanism which will assure that production data is validated by supervision personnel before it is released to management information systems, and that cost information is verified before it is released for use by optimization algorithms at levels 3 and 4.
Naming conventions for information available on the Industrial LAN are a key aspect of the "Application Layer" of the OSI/ISO model. This "Data Identity" issue is as essential as the physical communication standards, and in fact will extend beyond the Industrial environment into application packages which access the industrial LAN via gateways.
If we use the analogy of a telephone system, the lower layers of the Industrial LAN protocol provide a mechanism by which we can establish communications with any other party on the network. However, without a definition of data identity at the application level, we lack agreement on what the names will be of even the most common items.
A data value needs first and foremost a name. This should be a variable length, free format, designator. The ISA "Tagname" could be a useful model, but at the very least, and agreement is needed on a naming convention for such additional information as setpoints, 24-Hour Integrals, mean deviation, etc. It MUST NOT be a memory location, or an item number in an internal table. If this is done, (as is the case in most current products) then a simple reload of one device on the highway could invalidate the data base of every other device.
If such a naming standard is not adhered to, then what one manufacturer interpreted as a request for a setpoint change, another might see as a device reset. The effect on an industrial control highway would be as bad (or worse) than no communication at all! At best we would be back to the original problem that each manufacturer could talk only to his own products, and any data acquisition system would be required to talk all "dialects" on the highway.
The standard cannot stop at a naming convention for such data as current measurements, setpoints, and tuning constants. As shared operator interfaces develop, and as historical data storage moves into distributed boxes on the highway, the standard must include the additional dimension of time. This can have many forms. It may be simply a series of temperatures over the last hour, or, it may be a series of one day averages over the last month. It is therefore necessary to specify not only the period for which data is required, but the resolution also.
These "processed data types" can also include more sophisticated analysis such as Statistical Means and Deviations, "Snap Shots" of related variables, and "Windows" of values covering a period of interest such as an emergency shutdown.
Similarly, there is no reason to expect that all data will have only a single value. Many parameters such as a multicomponent chemical analysis, or the hundreds of X and Y positions that make up a shaft "orbit" only make sense when "associated" as an entity.
The number and kinds of data definitions are potentially large, and will vary with each installation. Obviously, without an agreed convention for naming both "raw" and "reduced" data, it will be impossible for the for the various processors in the network to effectively share this information. This is a lesson which was learned long ago with conventional "commercial" databases, and is no less valid for a real-time distributed data base implemented within a plant.
A role is required for each site which combines the tasks of the "data-base administrator" and "network administrator" in more traditional dataprocessing environments. This person defines the names and locations of all data on the network.
Initially only "primitive" data types would be defined, probably with only a small subset of key plant variables. As experience was gained, these would be developed to include more, and more sophisticated data, as justified in the particular installation.